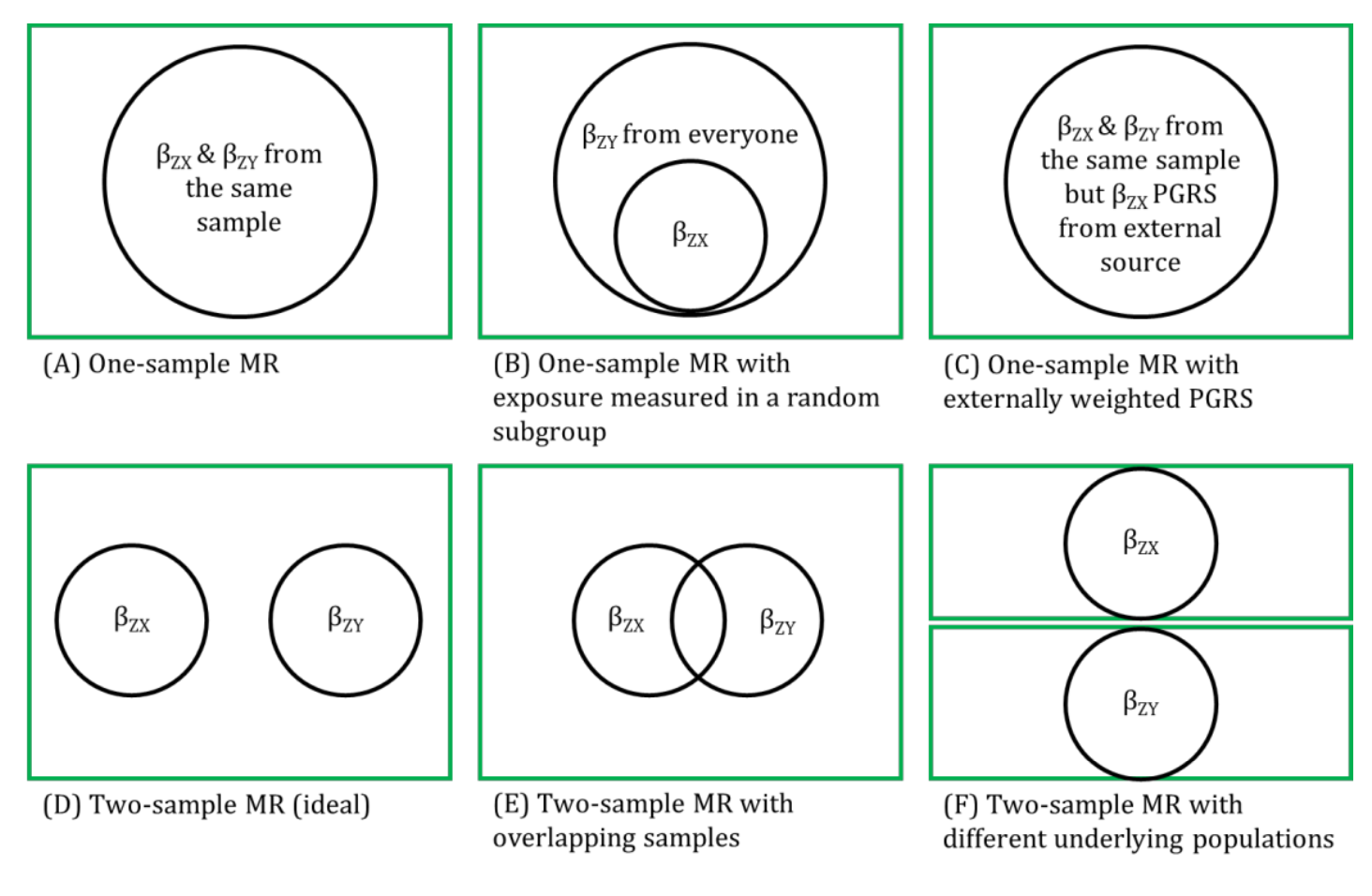
MR analyses in which the genetic instrumental variable (IV)-exposure association and genetic IV-outcome association are estimated from the same sample and individual-level data are used to derive the MR estimate.
Genetic IVs must fulfil the same MR assumptions. Genetic IVs (and weights for generating polygenic risk scores (PRSs), for example) associated with the exposure of interest are usually obtained from external data sources (e.g., a genome-wide association study (GWAS) of the exposure) and used within individual-level data (where the genetic IVs, exposure and outcome are measured) to generate a causal effect of the exposure on the outcome. In using individual-level data, there is more potential (than with two-sample MR) for assessing the associations between the genetic IV with observed confounders of the exposure-outcome association and exploring interactions, non-linear or subgroup effects. One-sample MR is more prone to data overfitting than two-sample MR. In one-sample MR, weak instrument bias will tend to bias the estimate towards the confounded multivariable regression estimate. Conversely, weak instrument bias in two-sample MR will tend to bias the estimate towards the null. Though, if there is overlap of participants in the two samples used for two-sample MR, the direction of any weak instrument bias in a two-sample setting will tend towards the confounded multivariable regression estimate (i.e., like in a one-sample setting with individual-level data) approximately proportional to the amount of overlap. The IV-exposure model can be miss-specified but the IV-outcome model must be correctly specified. NOTE: there are grey areas between one-sample MR and two-sample MR (e.g., in one-sample MR, when information from multiple data sources, such as betas from a GWAS that are used as weights in generating a PRS, is used to calculate an MR estimate with individual-level data, as shown in Figure 2.6). In fact, some MR studies use a mixture of analyses conducted in both individual- and summary-level data, sometimes using the same population sample. Therefore, the way in which these methods are described has evolved in the literature to focus on the data source being used in MR analyses rather than the number of samples - i.e., where "one-sample MR" is equivalent to "individual-level data MR" or "MR with individual-level data".
References
Other terms in 'Definition of MR and study designs':
- Bidirectional MR
- Factorial MR
- Instrumental variable (IV)
- Mendelian randomization (MR)
- MR for drug targets
- MR with binary exposures
- Multivariable MR
- Two-sample MR or MR with summary-level data
- Two-step or Mediation MR