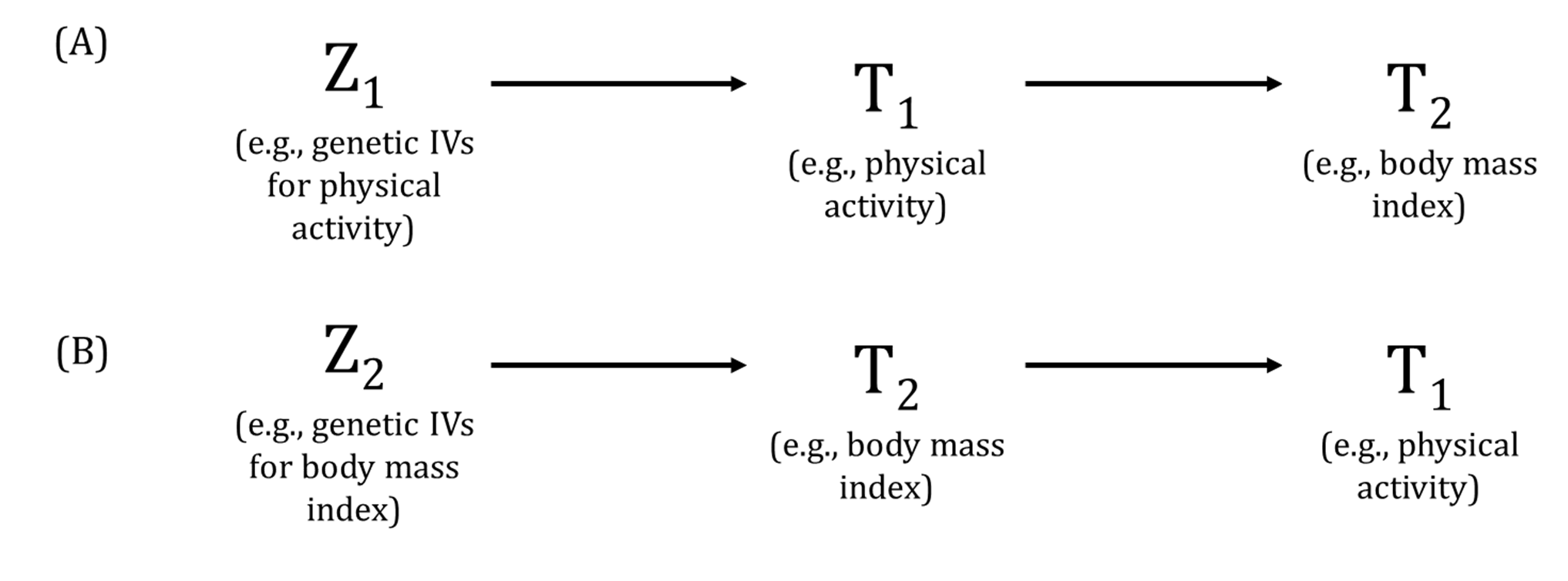
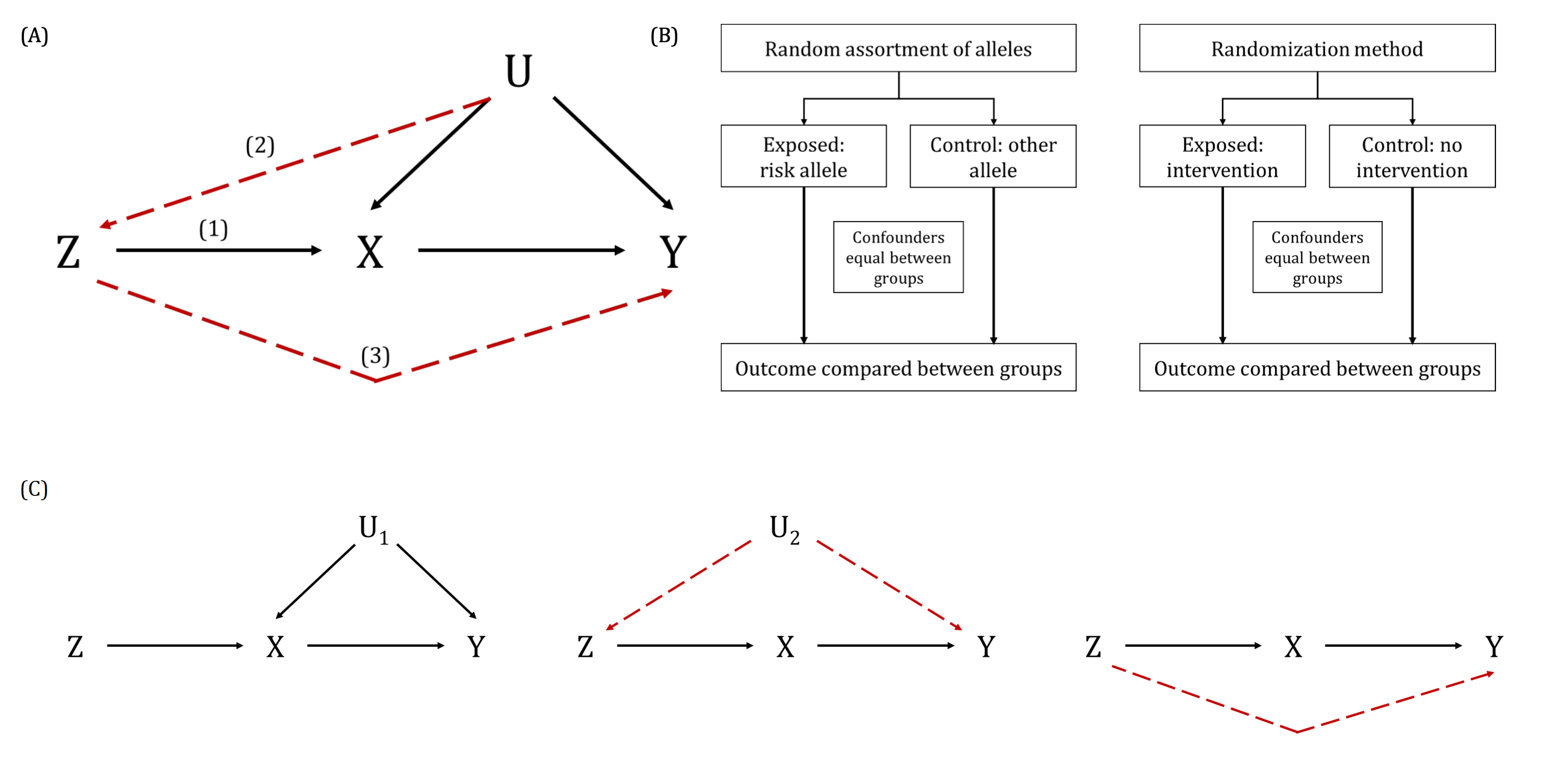
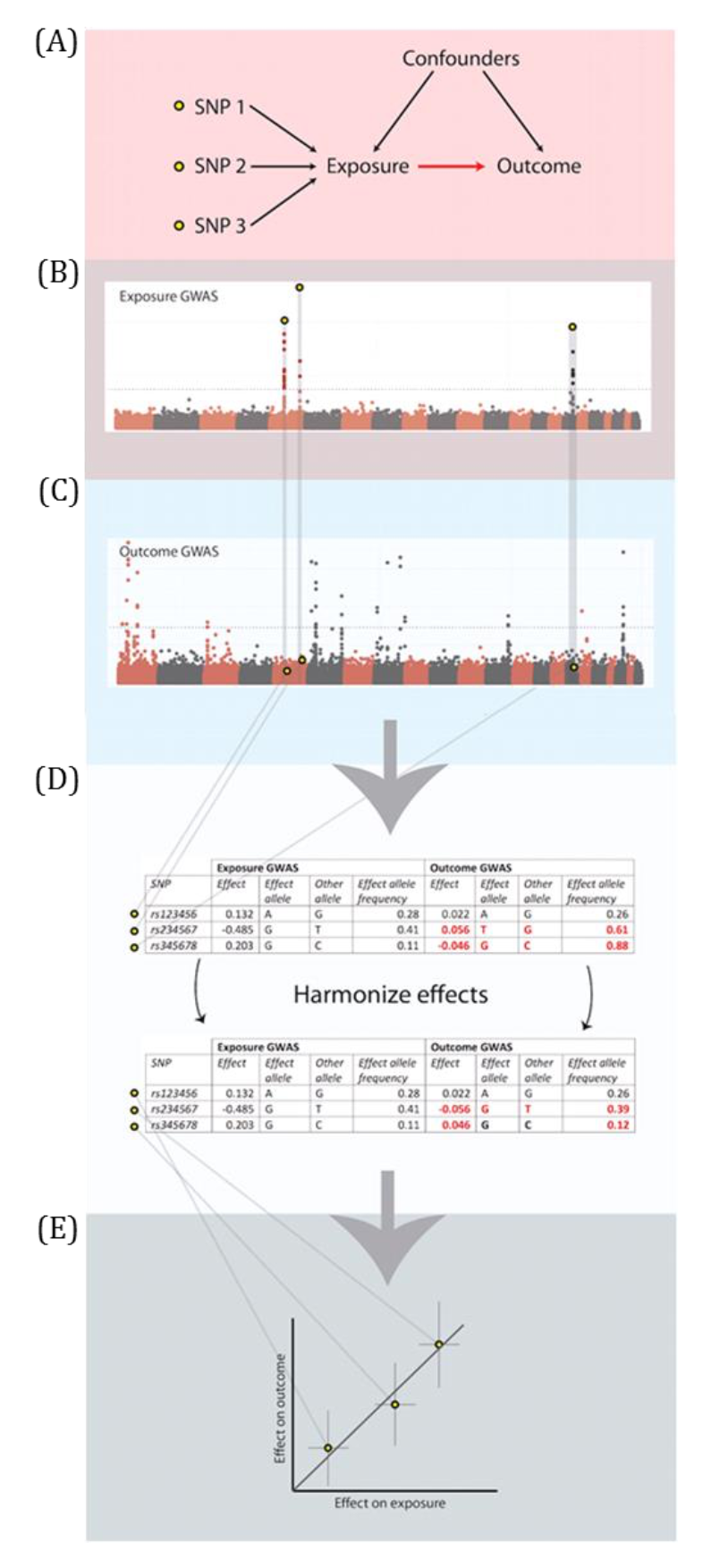
A DAG is a visual representation of potential causal relationships between variables. These relationships are demonstrated by nodes (representing variables) and arrows (a.k.a. edges or arches) between variables. The relationship between two variables in each DAG must be directed (i.e., there cannot be a bidirectional relationship). Relationships between all variables must be acyclic (i.e., a variable cannot have an impact on itself through any number of other variables).
DAGs are useful tools for explicitly demonstrating the underlying assumptions of a proposed analysis. Arrows are drawn between any two variables according to the following criteria: 1) An arrow from one variable to a second indicates that you assume that it is plausible that the first variable causes the second and 2) where there is no arrow between one variable and a second, this indicates that you assume that there is no causal relationship between the first and second variable. Thus, the three key assumptions of MR analyses are illustrated by an arrow from the instrumental variable (IV) to exposure; an absence of a variable that would have an arrow to the IV and to the outcome (i.e., no common cause of the IV and the outcome); and an absence of an arrow from the IV directly to the outcome.
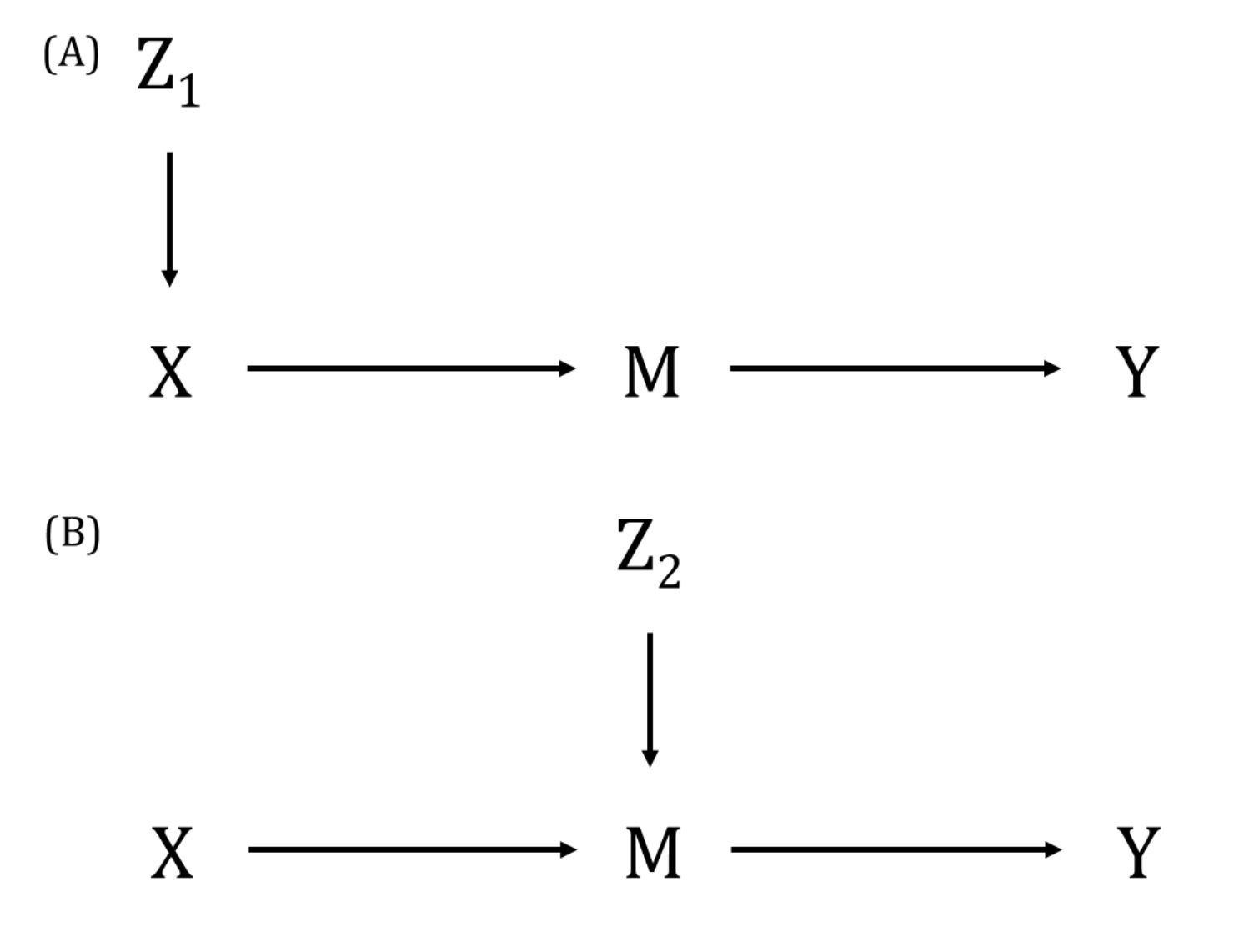
References
Other terms in 'Related study designs and approaches ':
- Candidate gene study
- Gene-Environment (G×E) interaction study
- Genetic colocalization
- Genome-wide association studies (GWASs)
- Genome-wide significance
- Imputation of genetic variants in GWASs
- Linkage disequilibrium (LD) score regression
- Replication
- Triangulation